
If you’ve ever heard anything about machine learning, chances are that you’ve heard the buzz words “Neural Networks.” These networks became incredibly popular due to the power that they offer with relative ease. Essentially, a single neural network is capable of simulating any function – including functions that we don’t know how to define precisely. Such functions are ubiquitous in the real world: from asking where people are in a given picture to detecting cancerous cells from an MRI. By setting our network’s weights appropriately, we can map any family of inputs to the corresponding outputs.
If this seems too good to be true, it’s because it is. While Neural Networks are capable of expressing all functions to an arbitrary precision, there are many “hyperparameters” of the network structure that need to be tuned first. Unfortunately, these hyperparameters are often like black magic: a small tweak can dramatically change the accuracy and training time of our neural networks.
How do Neural Networks function?
In the simplest case, a neural network is essentially two affine transformations stacked together.
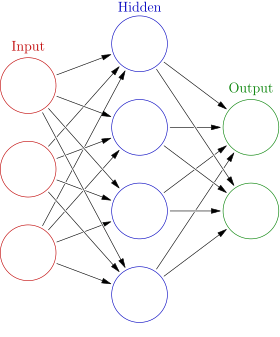
We first compute weights of hidden nodes using h = phi(W1 x) and then y = phi(W2 h) where W1 and W2 are matrices of carefully determined weights and phi is an “activation function.” The network is trained using gradient descent on the weight matrices to minimize the error between a subset of predetermined inputs and predetermined outputs. Even in this simple network, we have many hyperparameters to consider: how many hidden nodes are necessary, what activation function should we use, what variant of gradient descent is appropriate, etc.
Multilayer Neural Networks
Neural Networks were first introduced back in the 1980s. Back then, neural networks were often overlooked because of the high resource requirements needed to train the networks. Neural networks have made multiple resurgences since then primarily due to advances in computing power. However, one recent advancement brought neural networks back to the forefront of machine learning: deep networks.
Our simple two-layer model of a neural network is mathematically complete assuming enough hidden nodes are added. Another approach, however, is to instead keep the number of hidden nodes per layer small but increase the number of hidden layers. Mathematically, this operation is much more complicated, but achieves the same universal approximation result. Training a deep neural network offers significantly more challenges, but the neural network itself can represent nonlinear functions much more accurately with the same number of hidden nodes.
Deep Versus Wide
While many similar results exist for deep and wide neural networks, there has been surprisingly little research which explicitly compares the benefits and drawbacks of the two structures. Experimentally, recent research has demonstrated that deep networks are often more accurate than wide networks with the same number of nodes. Wide networks, however, have proven to be vastly easier to train. Perhaps the best intuition for this difference comes from recent research which demonstrates an exponential depth-width trade-off for implementing multiplication. In an attempt to understand the depth-width trade-offs of neural networks, I explored recent research describing both the benefits and drawbacks of both network structures. My findings can be found here.